

Introducing compiler optimizations for memory-safe & democratized modelling
In machine learning, speed matters but it is not the only limiting factor for today’s algorithms. Memory is also an important consideration where overflows can cause code executions to grind to a halt without producing any results, representing a significant waste of both human and computational resources.
Today’s models continue to grow in scale and complexity causing increased memory consumption requirements. This issue is becoming increasingly significant for machine learning practitioners, hampering their ability to work with machine learning algorithms.
To address these large memory requirements, previous approaches have focused on distributing computations across multiple resources, but this comes at the cost of requiring more hardware resources.
In our camera-ready paper, we consider three examples: sparse Gaussian process regression (SGPR), k-Nearest Neighbours (kNN), and Transformers.
In this blog post, we introduce a new XLA compiler extension developed in conjunction with researchers at Imperial College to help address this memory challenge. The tool will allow researchers to access the benefits of the machine learning algorithms, without incurring the cost of expensive large-memory hardware.
The resulting paper “Memory Safe Computations with XLA Compiler” was selected for the prestigious NeurIPs 2022 conference, which is scheduled for 28th November to 9th December 2022.
Introducing an extension to the XLA compiler
Compilers are an established tool to improve runtimes without requiring any user interventions. XLA is one such compiler, which integrates well with existing frameworks such as TensorFlow and PyTorch.
What’s more, XLA can optimize computational graphs in their entirety.
In the paper, we introduce several optimization strategies into the XLA optimization pipeline, aiming to limit the program’s memory footprint. We presented how existing software packages can take advantage of our extension to XLA (eXLA), demonstrating optimizations for k-nearest neighbours (kNN), sparse Gaussian process regression (SGPR) models and simple language Transformer models.
For example, we ran a kernel matrix vector product implementation with eXLA enabled, which allows a user to control the memory of an algorithm. We evaluated the expression in double precision on a Tesla V100 GPU with 32 GB of memory, and applied a range of memory limits.
In the figures below, we can see the peak memory consumption and execution time to evaluate the kernel matrix-vector product for different sizes, with different memory limits applied. Significantly, the memory constraints set by the user are not violated and the dataset sizes (which were randomly generated inputs in the experiment) that are used are far beyond the 32 GB memory capacity.


Gaussian processes are considered the gold standard method for performing regression with uncertainty estimates, and Secondmind is a leading expert in sparse GPs and their industrial applications. With our eXLA optimizations, SGPR was able to scale to much larger datasets, with more inducing points, compared to without eXLA.
We used the same Tesla V100 GPU with 32 GB of memory and ran two large datasets that are commonly used in Gaussian process research.
In the figures below, we can see that after around 800 inducing points, runs without eXLA fail with an “out of memory” error. With eXLA, we can scale to 10⁴ inducing points, resulting in significant performance improvements.

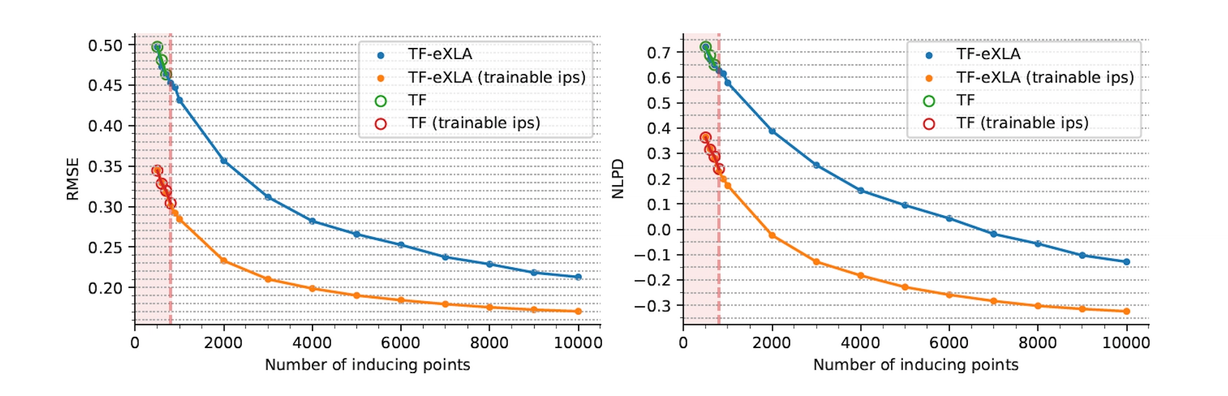
In other words, machine learning models compiled with eXLA ran on a greater scale, whereas their out-of-the-box implementations failed with “out of memory” errors. Crucially, we used existing software packages without modifying code, allowing researchers to plug in to this solution without any changes to their existing solutions.
This opens up the exciting possibility to probe the behaviour of machine learning models in regimes previously thought to be infeasible, and on cheap hardware, or distributing them across GPUs, without increasing the software complexity.
It is worth noting that this paper is still only a demonstration of what these introduced memory optimizations could achieve. Many more optimizations could be added, further increasing the capabilities of compilers like XLA to help scientists and researchers increase the efficiency of their machine learning algorithms.
This is also an automated, under-the-hood solution, which helps scientists to focus on their own areas of expertise, and find the best results without expensive computation.
If you’d like to find out more about our work and how we’re helping machine learning researchers and automotive engineers find the right solutions, click here.