Secondmind Active Learning explained
Machine Learning Researcher Max Mowbray explains how Secondmind Active Learning cuts data requirements to combat engineering complexity and accelerate workflows

Modern engineering is challenged by complexity. As engineers push for optimal performance, every new sensor or control loop adds a fresh dimension to the development process. This triggers the ‘curse of dimensionality’: a mathematical reality where the volume of possibilities grows so fast that traditional engineering intuition evaporates.
Intuitively, an engineer might think they can manage this by testing just the high and low values of each setting. It feels like a sensible way to cover the bases. But it is a mathematical trap. You don’t need hundreds of variables to be doomed. Even with a handful of dimensions, the math turns against you. Assuming each experiment takes just one minute:
2 dimensions: 4 experiments (4 minutes).
10 dimensions: 1,024 experiments (17 hours).
20 dimensions: 1,048,576 experiments (2 years).
100 dimensions: More experiments than there are atoms in the universe.
And this is just testing the minimum and maximum values for each dimension! An exhaustive search of all possible combinations of values, say 10 per dimension, would already bring the cost of exploring 10 parameters to about… 19,000 years.
While that timeframe is clearly impossible for any real-world project, the scale of complexity it represents is the practical reality in fields like powertrain calibration. Here, variables like spark timing, fuel injection pressure, and boost levels constitute an experimental design space so vast that data points, no matter how many you collect, are always sparse. This means that any fixed approach to testing or simulation is essentially flying blind, likely to miss the critical performance peaks and hidden failure boundaries that define a successful design.
Because we cannot brute-force our way to a solution, we can no longer rely on traditional experiment and learning cycles. To solve modern engineering problems, we need a way to strategically pick the most informative experiments. In this high-dimensional environment, data-efficient machine learning becomes a critical engineering tool for navigating this complexity.
The traditional playbook: DoE and response surfaces
To navigate the design space, engineers have traditionally relied on two core pillars: Design of Experiments (DoE) and Response Surface Methodology (RSM).
DoE provides a structured way to select data points, often using space-filling techniques like Latin Hypercube Sampling, to ensure a broad view of the system. RSM then takes this data to fit a mathematical ‘surface’ (a model) over the results, allowing engineers to interpolate between data points and predict performance in unsampled areas.
The breakdown of static planning
While effective for lower-dimensional problems, this sequential plan-then-test approach faces significant hurdles as system complexity increases:
Structural sparsity: In higher dimensions, even a well-distributed static design remains mathematically sparse. The distance between points becomes so large that critical nonlinearities and performance peaks can easily fall through the cracks of the DoE.
Model-bias and structural constraints: RSM often requires a prior choice of model structure, such as a polynomial. This effectively forces the system to conform to a predefined shape. If the underlying physics are more complex than the assumed formula, the model will fundamentally misrepresent the system behavior.
Data-inefficiency: Because the sampling plan is fixed at the start, resources are often wasted. A static plan spends as much time measuring all regions of the experimental space, giving the same resource to experiments where the physics show low and high-sensitivity to the experimental design.
The paradox of global accuracy
These limitations stem from a methodological requirement: the pursuit of a complete map. Traditional tools force the engineer to try and characterize the global behaviour of complex systems. However, the curse of dimensionality makes this impossible, as accurately mapping such a vast space would require a prohibitive and unattainable amount of data When you spread a limited number of experiments across a vast space, you are left with a representation that is global but with a high degree of real system mismatch. While such a model might support high-level generalities, it lacks the resolution needed for the precise decisions that lead to an optimal outcome.
The solution: Goal-oriented Active Learning
To be efficient, we must accept that we do not need to learn everything perfectly. We only need to know enough to identify where the good solutions are not. By quickly dismissing unpromising regions, we can concentrate efforts on the narrow areas where the best solutions actually reside.
This requires a shift from global mapping to goal-oriented mapping. We need a system that understands the objective of the project and uses that information to decide where to sample next. This transforms the modeling process from a passive recording of data into an active pursuit of the solution.
This is where Secondmind Active Learning comes in, the core technology powering our cloud-native software. It is an advanced machine learning system designed to identify the most informative data to meet design objectives and constraints. Rather than aiming for global perfection, it builds high-fidelity approximations focused on the areas that actually drive industrial decision-making.
The role of uncertainty quantification
The key driver for this approach is uncertainty quantification - a capability overlooked from traditional RSM and, surprisingly, from most modern deep learning approaches.
Standard neural networks and polynomial surfaces are often overconfident; they provide a prediction but cannot quantify their own ignorance. Without a formal measure of predictive uncertainty, a model cannot distinguish between a region it has mastered and a region it has never seen.
Secondmind Active Learning thrives on this self-awareness. By using probabilistic models that identify where they are most uncertain, the system can balance exploring unknown territory with refining known high-performance areas. This allows Secondmind to focus solely on the information required to reach the right decision, collapsing the search space and finding optimal solutions with a fraction of the data.
Secondmind Active Learning in practice
Secondmind transforms this theory into a cloud-native workflow. Instead of a rigid plan, the system iterates through a continuous, four-step feedback loop:
Acquire: The loop begins with initial "seed" data -a small set of existing measurements or simulations.
Model: A probabilistic model is built in the cloud. With each iteration, it updates its understanding of the system, refining its predictions as new data arrives.
Analyze: The system evaluates the remaining trade-offs and, crucially, its own uncertainty. It identifies where it is confident and where it is guessing.
Design: Secondmind identifies the most informative area to sample next. It prioritizes points that resolve the most uncertainty or offer the highest potential for optimization.
This next experiment is then executed - whether in a physical test cell, a simulation environment, or a software control loop - and the results are fed back into the model. The process repeats until the design requirements are met.
From assumptions to insights
While this iterative workflow shares some DNA with traditional model-based approaches, the underlying technology is fundamentally different. Traditional, static model-based DoE rely on fixed rules and rigid model structures that often struggle with the nonlinearities of modern systems.
Secondmind Active Learning utilizes Bayesian inference and highly flexible machine learning models. Instead of forcing the data to fit a predefined polynomial shape, the model learns the system’s true behavior directly from the data. By using the model's own quantified uncertainty to direct the search, the system ignores irrelevant regions and prioritizes experiments that provide the highest informational value.
The transition from fixed rules to adaptive insights is best illustrated by comparing how different strategies navigate the same space.
As shown below, where a static grid or an assumption-led model might waste dozens of experiments on "flat" regions or miss a sharp performance peak entirely, Active Learning clusters its efforts exactly where the physics are most complex and the potential for optimization is highest.

While a traditional brute force approach might blindly and slowly populate a grid, Secondmind's intelligent, automated process has already identified the "safe" operating zones (Low knock) and the "danger" zones (High knock) for fuel efficiency more effectively.
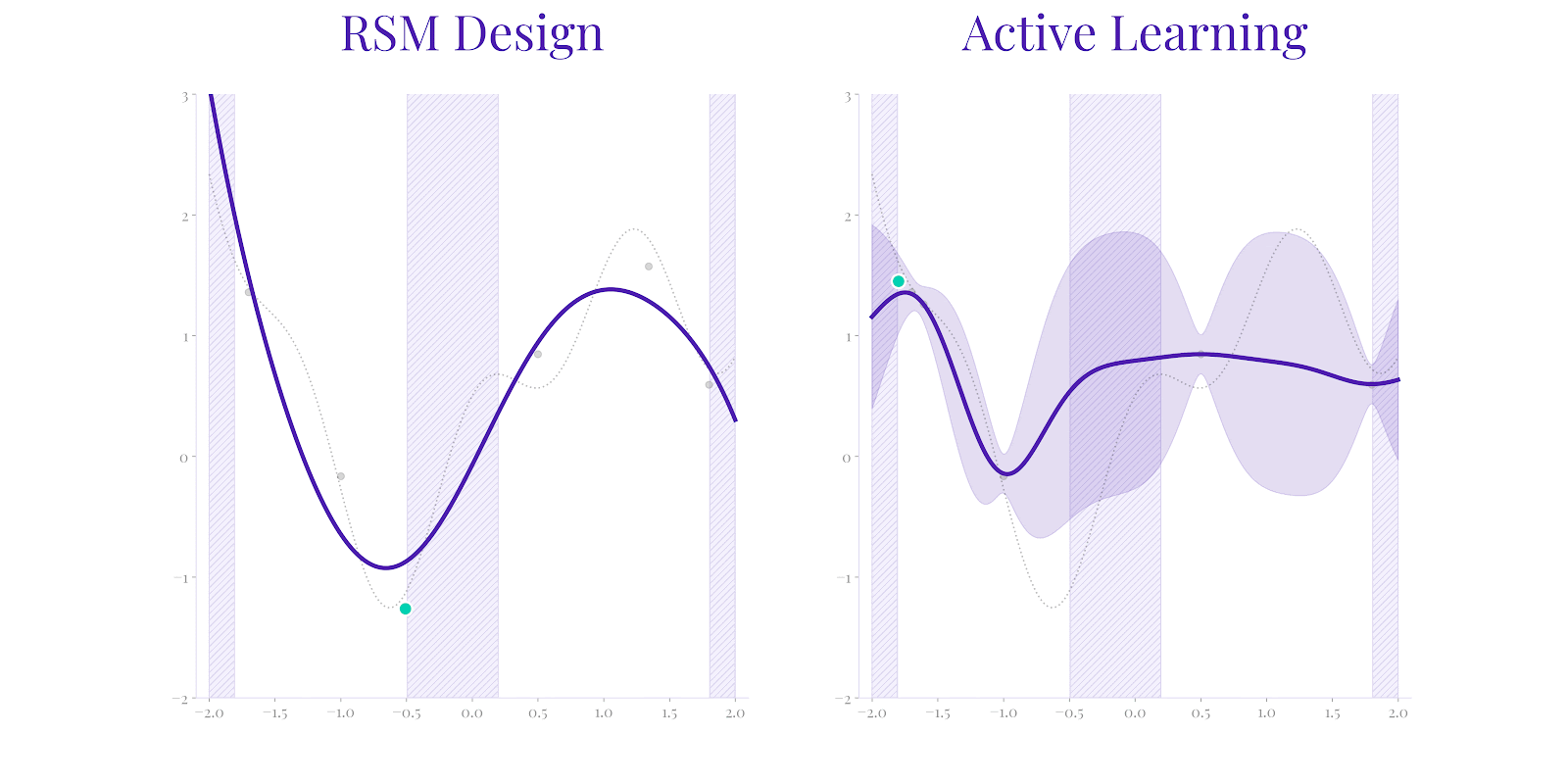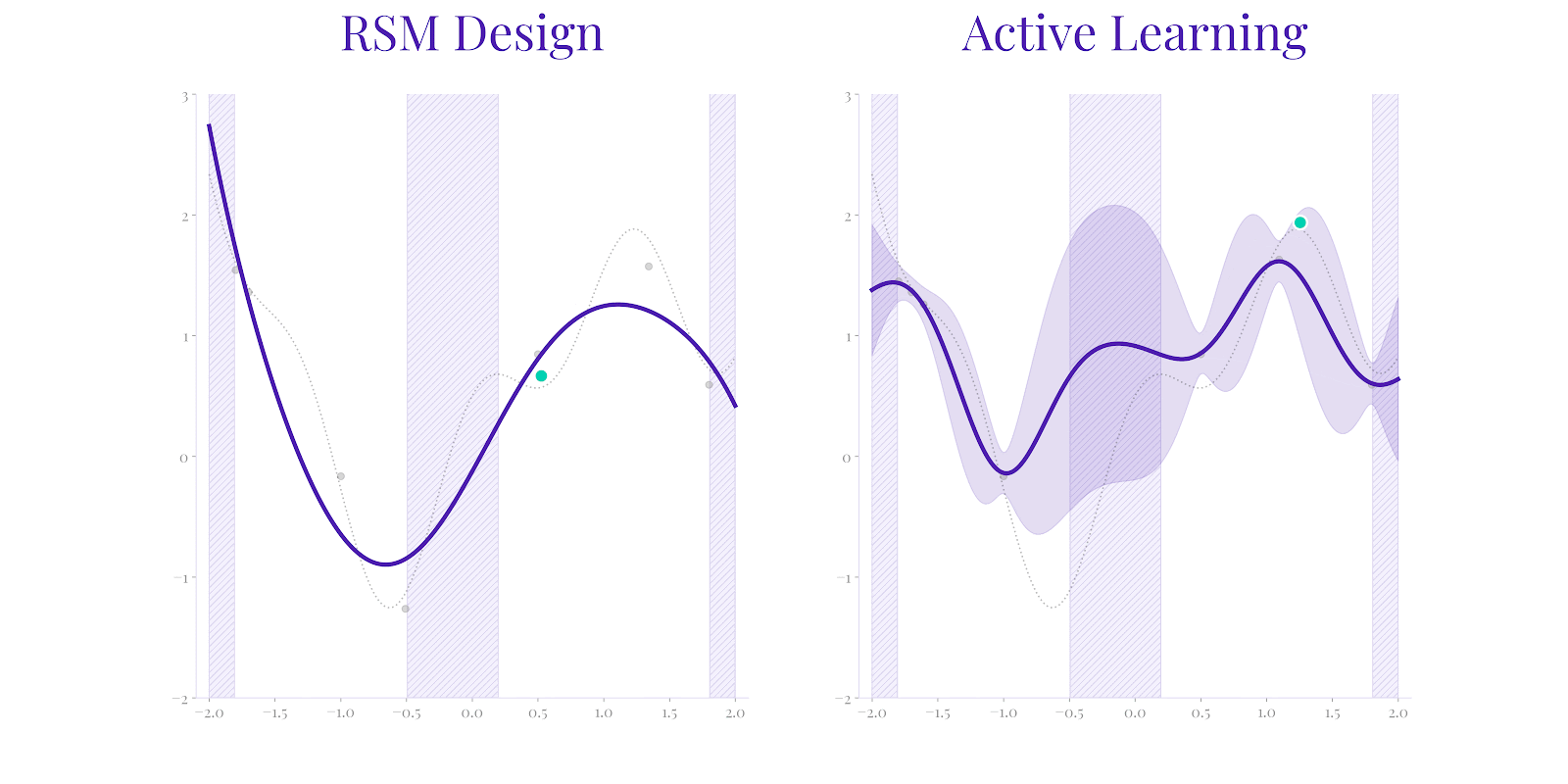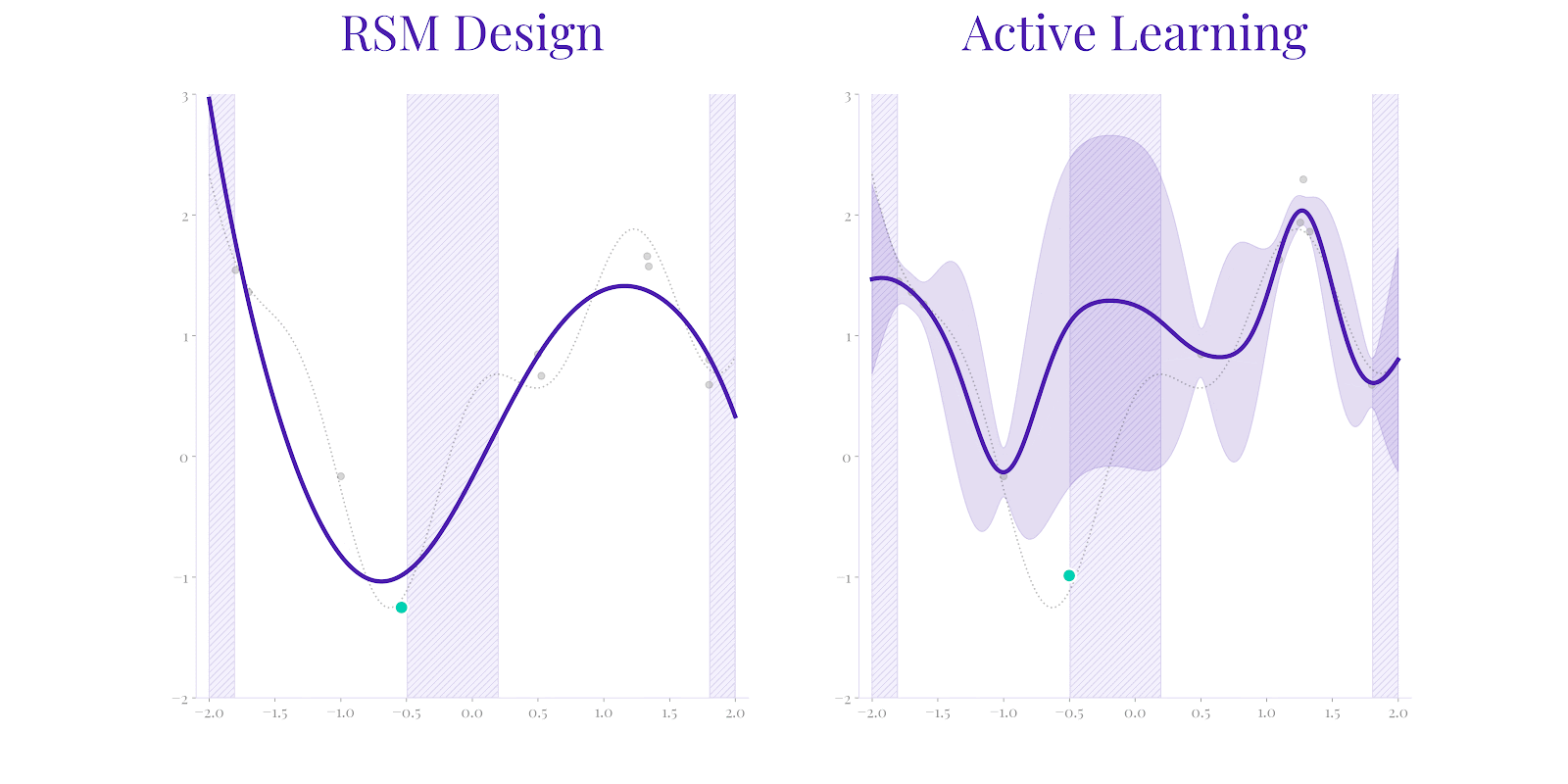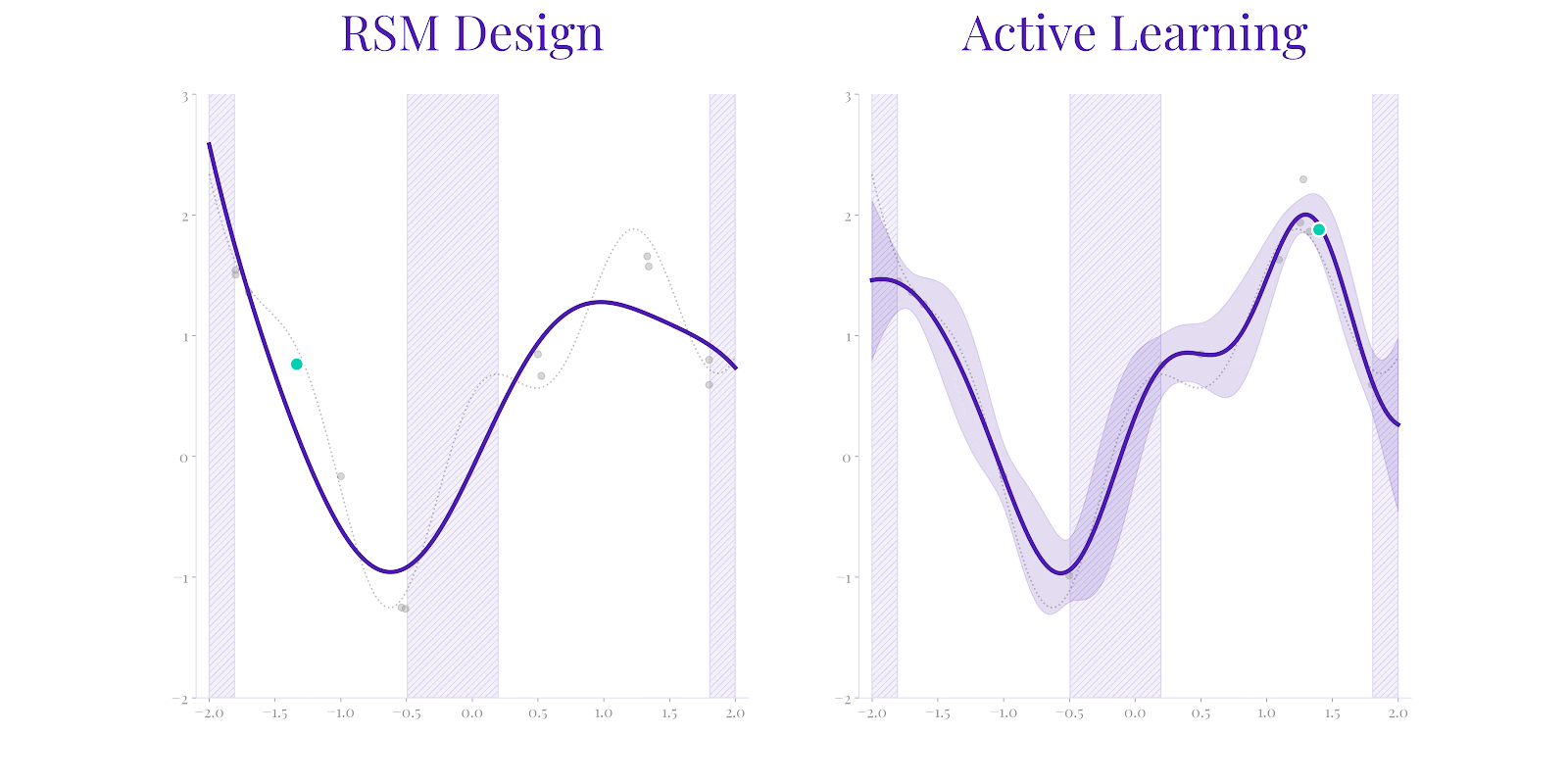
While RSM (left) attempts to calibrate an approximation with fixed structure, it can fail to represent the true system behavior (dotted line) if limited by assumptions. Secondmind Active Learning (right) identifies both the ground truth more rapidly by adaptively exploring uncertainty, as well as correctly identifying the set of potential function maximizers.
Comparison: different DoE approaches at-a-glance
Feature | Brute-force DoE | Static DoE + RSM | Secondmind Active Learning |
Philosophy | Coverage-focused | Assumption-focused | Insights-focused |
Best use cases | Simple systems (2-4 variables) | Weakly nonlinear systems | High-dimensional spaces and high degrees of nonlinearity |
Scalability | Very poor (exponential growth) | Poor (equation-bound) | High (fully scalable) |
Data-efficiency | Very poor - high resource wastage | Moderate and variable | High - up to 80% less experiments required to achieve same or better results |
Proven impact for R&D leaders
As system complexity increases, the "curse of dimensionality" has become a barrier to progress. By focusing only on the experiments that move the needle, Secondmind Active Learning allows R&D leaders to bypass the traditional trade-off between development speed and system optimization.
Recent examples of how this translates to the bottom line:
A major automotive OEM achieved 59.7% workload efficiency gains by using Secondmind to optimize powertrain transmissions, delivering high-precision results in just 4 hours.
A North American Tier 1 powertrain supplier reduced fuel consumption by 67% and test-cell occupancy from 4 weeks to 1.5 weeks while exploring a 2.3x larger design space using Secondmind.
An automotive OEM customer reduced e-motor BOM cost by $27 USD per unit from lower grade magnet and less sound insulation, without negatively impacting torque and cabin comfort - with $11million USD projected annual cost savings in full production.
In high-stakes R&D, the real bottleneck is the time and effort lost on experiments that prove unreliable or the effort spent unnecessarily navigating data irrelevant to your problem. Whether waiting for a physical test bench to clear its queue or a complex simulation cluster to return a result, every redundant data point represents a delay in the design cycle.
When Secondmind reduces data requirements by 80%, we are directing focus to the most relevant information and providing a clear line through the complexity. In doing so, we help engineering teams reclaim their most valuable resource: time. By turning weeks of scheduled experiments into a morning of automated, actionable insight, we empower teams to stop managing data logistics and start solving high-value system challenges.

Learn more
Want to see how Secondmind can help you with your most complex engineering challenges?



